如何将8B LLMs 1M tokens TTFT 优化至20s
Disclaimer: 以下内容仅代表个人观点,不代表我所在公司或者团队的观点。
此外本文也不讨论任何关于 Long-context LLMs 强还是RAG强的问题。
假如你想将一个8B的模型,1 million tokens的 TTFT 优化至20s,你会
- A. 使用Gated-Linear RNN or SSM (e.g. Mamba-2, RetNet, RWKV, DeltaNet), Sparse Attention (e.g. SW, BigBrid, LongNet) or Linear Attention;
- B. 使用Hybird Model (e.g. Jamba, Samba);
- C. Scale up to 65+ x A100 or H100;
- D. 利用 Memory-based, Recurrent-based, or Cluster-based 降低 Attention 复杂度;
- E. 让用户等一等,等到第二轮对话就好了;
- F. 试一试 MInference (误;
相对FlashAttention需要加速多少倍
让我们做个简单的计算题,按照 fp16 8B Transformer 计算, 一张 A100 的 fp16 TFLOPs = 312 TFLOPs
\begin{equation}\textbf{理论单卡TTFT} = \frac{\text{1M prompt 所需要的FLOPs}}{\text{A100的fp16 TFLOPs}} = \frac{1M \times \left(2 \times 8B + 2 \times 32 \text{ layers} \times 1M \times 4096 \text{ dim} + \text{softmax 部分} \right)}{312 \text{ TFLOPs}} = 14.52 \text{ mins} \end{equation}
但是考虑到 Transformers 计算中存在一些 kernel 优化,同时读写,同步等待,memory movement 等因素实际的 TTFT 会比这个数值慢1.6-2倍左右 (视framework而定, TensorRT-LLM > vLLM > HF)
那么 单卡的估计上限 \begin{equation} = 14.52 \text{ mins} \times 1.5 = 21.78 \text{ mins}\end{equation}
于是如果不考虑 TP and Sequence Parallel 的通信开销 尤其是节点间通信开销,那么我们最少需要 65 张A100
如果你碰巧财力雄厚,你也可以用 20+张H100 SXM 实现相同的事情。
(Quantation 需要除以一个系数)
那么假定只有8张A100, 为了实现1M tokens 20s 的TTFT,起码需要实现相对于FlashAttention 8x的加速。
为了实现这个目的,由于prefilling 阶段为computation bound,优化目标等价于降低8x的Attention FLOPs。
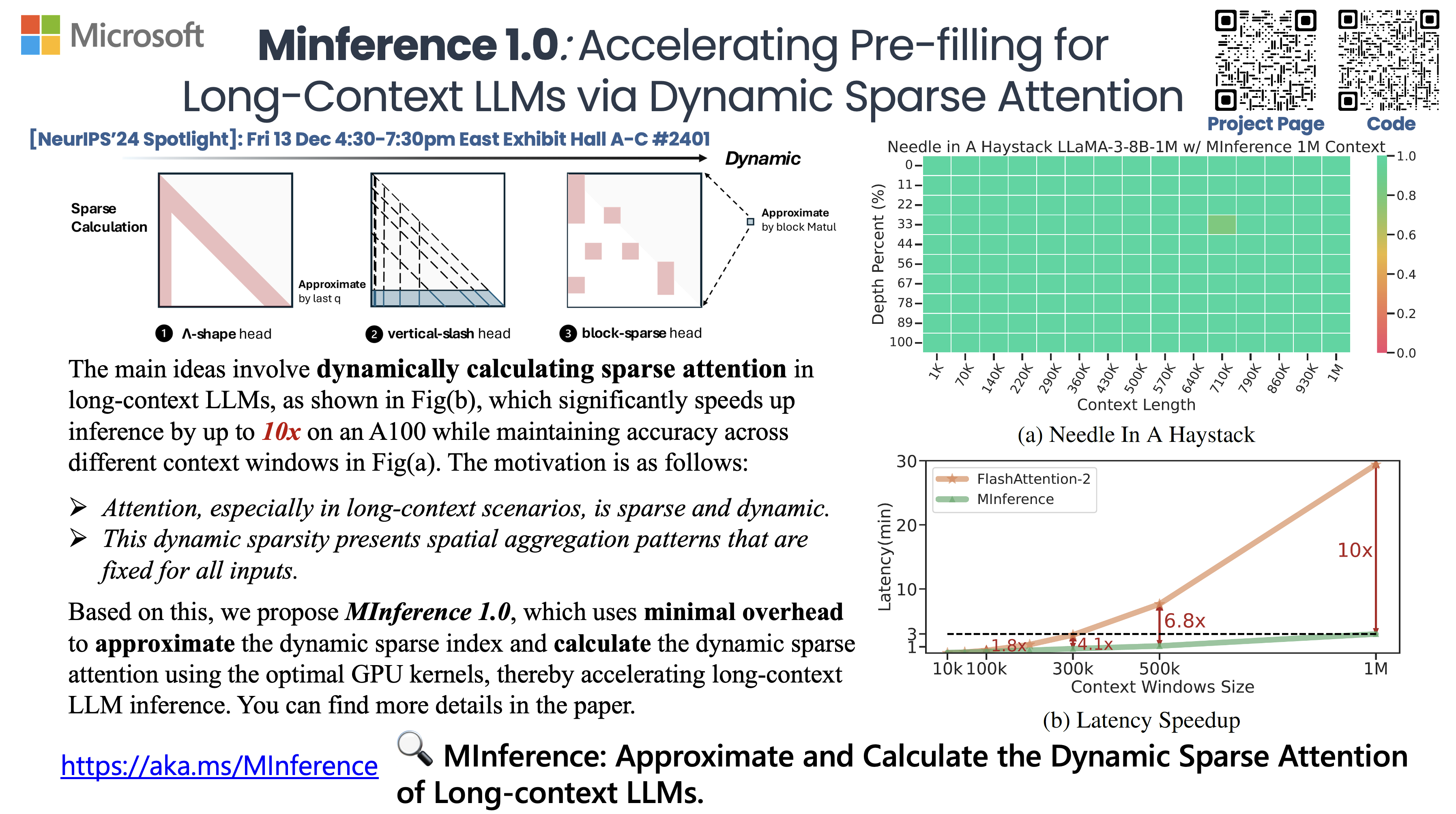
先说结论,使用MInference,利用Long-context Attention中的动态稀疏性,只需要8xA100 就能做到20+s的TTFT,并且Accuracy性能几乎相同,尤其是在一些非常动态的long-context 任务中。
- MInference Project Page: https://aka.ms/MInference
- Code: https://github.com/microsoft/MInference
- Demo: https://huggingface.co/spaces/microsoft/MInference
How to co-design the algorithm and system?
首先,优化的Intution是什么:Attention的稀疏性,由于Softmax,以及Long-context 带来的极度稀疏性。(这点很多工作已经分析过了,e.g. StreamingLLM,SparQ,TriForce)
那么优化的目标就是利用这种先验的稀疏性,设计GPU高效且Recall准确的稀疏Attention算法。
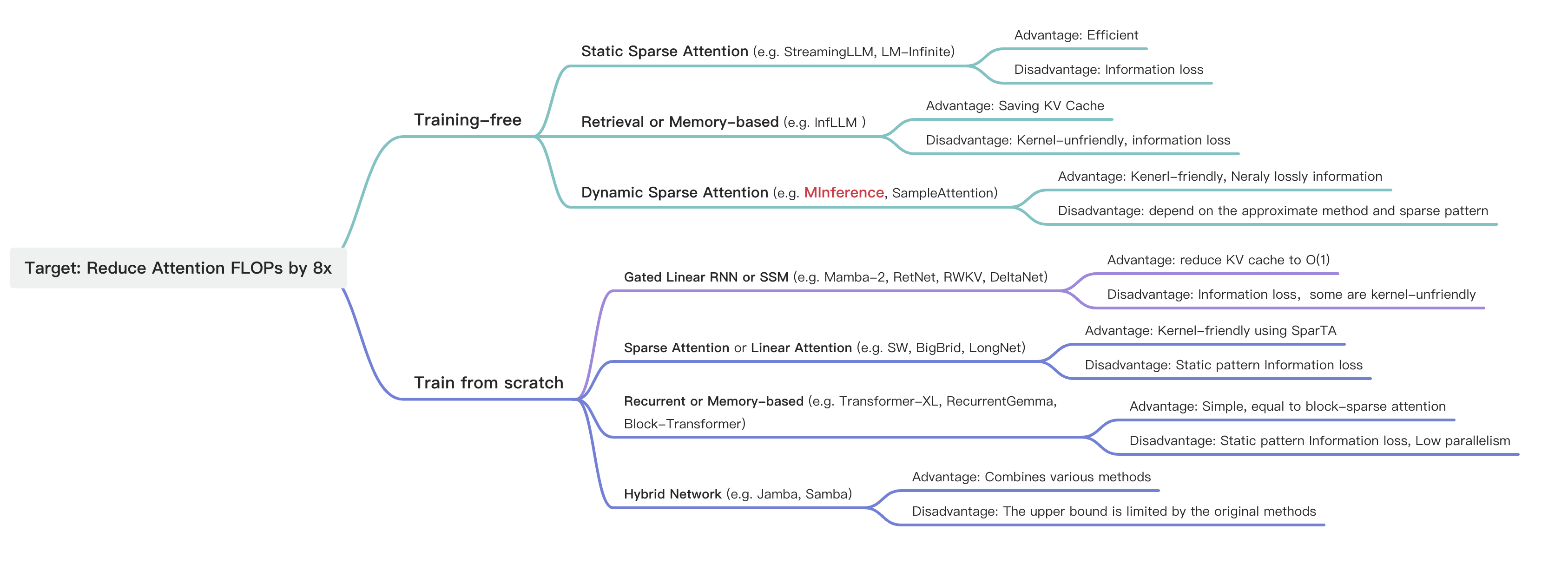
回顾目前存在的一些Efficient Long-context LLMs 方法,如上图。
简单的Brainstorm一下,对于Multi-head Attention 这个结构,它是由layer 层每层两个[batch size, head number, seqlen, head dim] 的Q 与 K 矩阵进行Matmul。
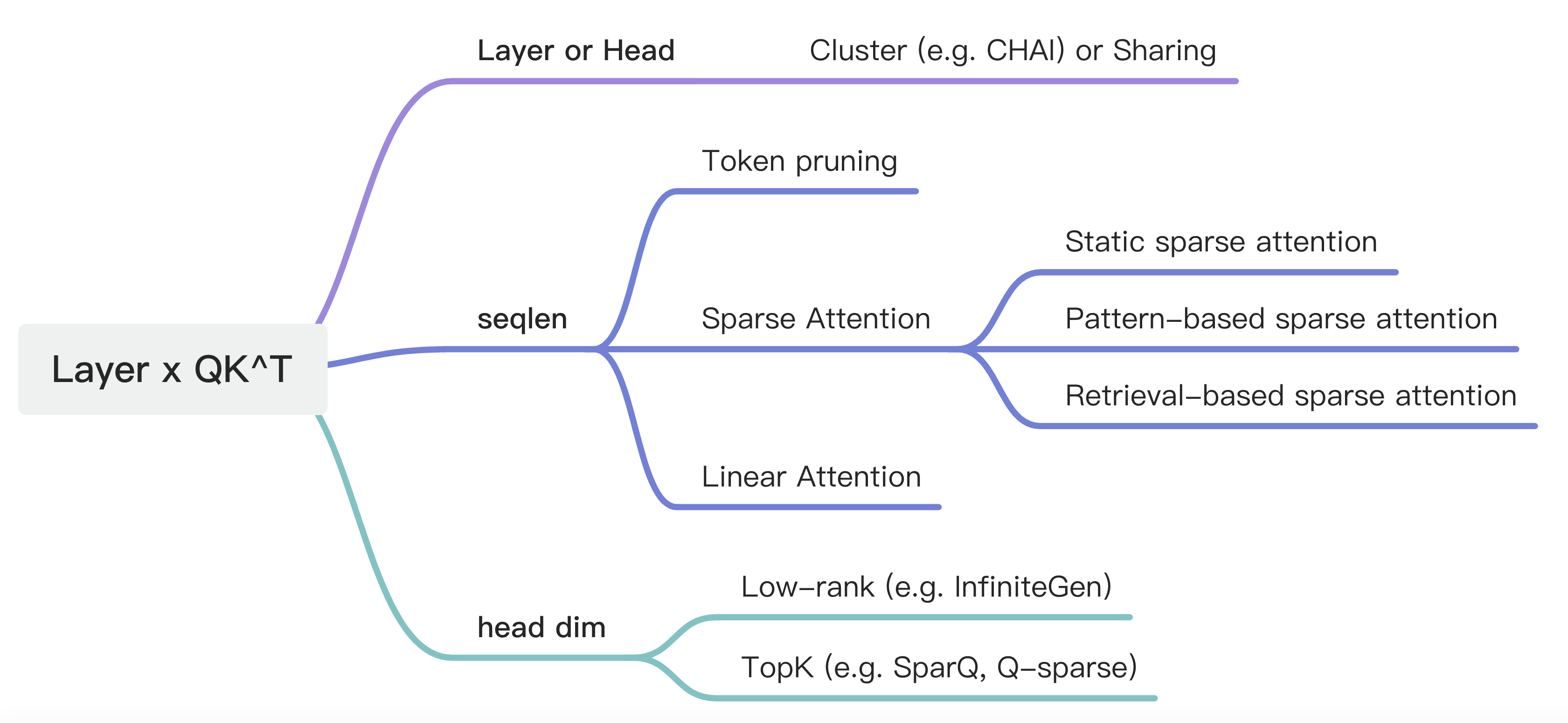
可以从Head level 进行聚类或者sharing,可以从seqlen 出发,对token pruning,Sparse Attention计算,或者Linear Attention,也可以在head dim上操作,low-rank或者topK。
我们将优化方向收敛到training-free的Sparse attention based methods,(毕竟做加法难做减法容易。
Sparse Attention中三类方法,Static sparse Attention performance loss大,无法完成dyanmic 的任务,例如Needle In A Haystack和KV retrieval。这类方法不work的根本原因也是Attention本身非常动态的,这才能发挥其N^2对信息的获取能力。
Retrieval-based sparse attention 的motivation也很直接,既然Attention是极度稀疏的,有没有办法利用比较小的overhead来获取每一个Q对应的TopK K的index,比如说在head dim上进行优化,例如SparQ (不过其仅做在decoding stage)。但这类方法是Kernel-unfriendly的,TopK这个操作对于GPU来说不一定比CPU强。其次从算法层面,这类方法需要用很小的代价获得比较高的TopK index 召回率,目前还是一个难点,SparQ,TopK的计算量就高达1/8 N^2, 很难scale 到long-context 中。
于是有没有办法设计一种kernel-friendly 的dynamic sparse attention method。
- kernel-friendly 要求sparse pattern 具有一定空间聚集性,并且block size 较大,能够调用Tensor core
- dynamic sparse 要求 我们能利用极小的overhead 在线确定并且build dynamic sparse index
- sparse attention 要求LLMs 原始的Attention pattern中具有较大的稀疏率
于是根据以上principle 我们提出了MInference,一种利用dynamic sparse attention 的training free and kernel-friendly的long-context LLMs nearly loss accelerate method。
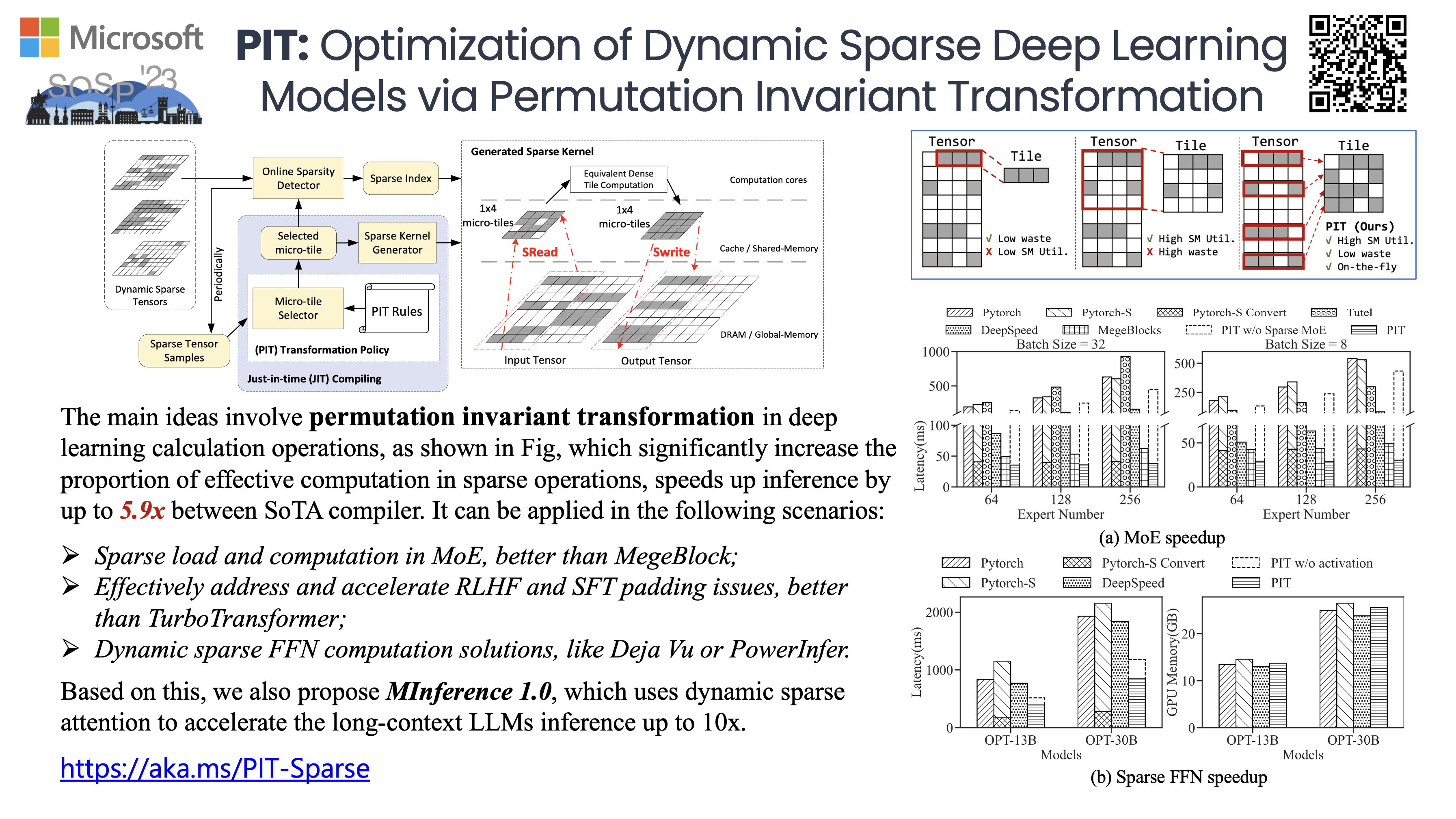
得益于我们之前在sparse attention 优化尤其是dynamic sparse attention方向上的工作,例如PIT。我们能最多端到端加速1M tokens LLMs TTFT 10x。
我这里特别想强调一下PIT的powerful,(感觉LLMs community 不太关心MLSys 领域的工作)他可以被用作
- MoE的稀疏load和稀疏计算,MegeBlocks的同期工作;
- 有效解决/加速 RLHF or SFT padding 问题,比TurboTransformer更好的解决方案;
- Deja Vu or PowerInfer dynamic sparse FFN 计算的解决方案。
MInference具体细节可以参考 @九号 yucheng的blog and 机器之心
或者我们的paper
我就不在这赘述了。
我在这里想更多的讨论一下paper中没有写到的一些highly insights。
Is dynamic sparse attention is future?
我们不确定这个方向是不是future,MInference 在short context 下性能可能还不如现有的vLLM or TensorRT-LLM. 但我们可以确定它确实是现行50K-1M context LLMs 加速的一个有效的可行解。
第一,我们在这个节点看到了一些同期工作,有些idea都非常相似,我们确定这个方向是被大家发现都能work的。
第二,MInference展现出来比较好的泛化性。首先是仅需要单条sample 搜索出最优config,具有非常好的跨任务和跨长度泛化性。其次,MInference展现出非常好的跨模型的泛化性。我们测试了open-source powerful的Long-context LLMs, including LLaMA-3-8B-1M, GLM-4-9B-1M, Yi-200K, Phi-3-mini-128K, Qwen2-7B-128K均表现出非常好的性能。另外,我们最近也收到某LLMs厂在内部模型上测试结果非常好的反馈。
Which pattern is the most important, and why?
Slash, slash pattern 是这三个pattern 中最重要的pattern。其实这个pattern在BERT时代就有被发现,但是由于加速困难,一直没有被很好利用。
那么Slash pattern 有没有什么具体含义。首先,这个pattern 肯定和RoPE有一定关系,RoPE的pattern就长这样。其次,它肯定不只是和RoPE相关,毕竟BERT,T5,MLLM里面都有这种pattern。我们倾向于将其理解为在attention中的某种信息通道,关注了等间隔的一些信息。
Is this method in conflict with KV cache compression, or can it be used in KV cache reuse scenarios?
MInference与KV cache compression methods 是orthogonal. 我们在paper中做了和SnapKV一起使用的实验,结果还会比SnapKV还会更好一些。
我们也测试了multi-turn dialogue 场景下,使用MInference的性能,在大部分任务中均表现较好,后续会更新相关结果。
How to evaluate the long-context LLMs abaility?
需要对LLMs在retrieval,general tasks,including QA,Summarization,Code, math reasoning等进行测试。
而retrieval 相关能力目前是各种方法性能差异明显的domain。从难度而言,KV retrieval > Needle in a Haystack > Retrieval.Number > Retrieval PassKey。对于后三者LLMs 是可以通过SFT 提前感知到语义信息变化的区域和潜在Question,从而实现较好的performance。而KV retrieval 这种非常动态的任务是极难处理的。
What different bettwen MInference, with SSM, Linear Attention, and Sparse Attention?
部分Gated Linear RNN 可以等价为Sparse Attention with KV cache compression. 其对prompt tokens信息压缩能力受限于先验的sparse pattern中 inductive bias。
不过总的来说,从powerful Models 做减法比单纯做加法简单一些。不过未来Gated Linear RNN 一定会有更好的/更逼近 full attention 的 performance。
Can pre-filling using SSM or SW and decoding using full attention be a solution?
我直觉是目前SSM or SW 拼接dense decoding 不能很好的进行正常推理。主要原因是先验的稀疏信息对Information 压缩损失较大。其次,from scratch的sparse attention 可能可以cover到一些动态pattern,需要更多的实验验证。
How to Optimize KV Cache in Decoding?
这是一个非常大的topic,我们下次再写(tao TODO