LLMLingua | Explore the special language for LLMs via Prompt Compression
News
- 🎈 We launched a project page showcasing real-world case studies, including RAG, Online Meetings, CoT, and Code;
- 👨🦯 We have launched a series of examples in the './examples' folder, which include RAG, Online Meeting, CoT, Code, and RAG using LlamaIndex;
- 👾 LongLLMLingua has been incorporated into the LlamaIndex pipeline, which is a widely used RAG framework.
Tl;DR:
LLMLingua, that uses a well-trained small language model after alignment, such as GPT2-small or LLaMA-7B, to detect the unimportant tokens in the prompt and enable inference with the compressed prompt in black-box LLMs, achieving up to 20x compression with minimal performance loss.
LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models (EMNLP 2023)
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang and Lili Qiu
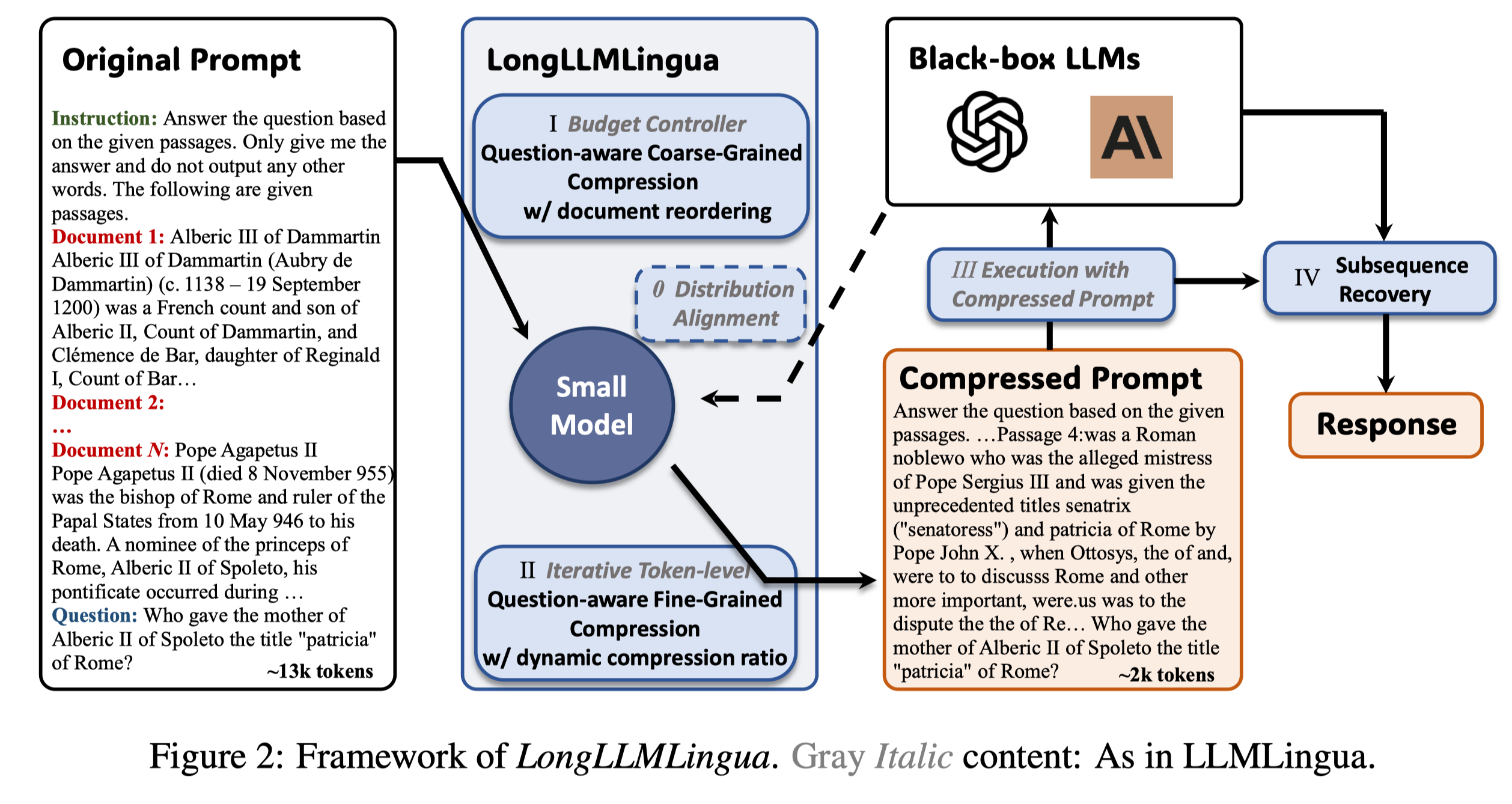
LongLLMLingua is a method that enhances LLMs' ability to perceive key information in long-context scenarios using prompt compression, achieving up to $28.5 in cost savings per 1,000 samples while also improving performance.
LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression (Under Review)
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang and Lili Qiu
The following content represents personal views and does not represent the views of the company or team I belong to.
Since this is a blog, let's change our approach and talk about our understanding of this work from a high-level perspective.
First of all, thanks to @九号 for his previous sharing, which inspired some of the work we did on this topic.
The title and the name LLMLingua actually express one of our goals, to construct a language exclusive to LLMs in some way.
This language is likely to be difficult for humans to understand, but LLMs can understand it well, so that some interesting things can be done on this language.
For example, conveying more information with fewer bits, or even conveying more efficient information to LLMs, thereby improving the performance of LLMs."
And we chose to approach this goal through Prompt compression.
Moreover, it makes a lot of sense to do this through Prompt compression, firstly because Natural Language itself is redundant, especially in spoken language, and secondly because ChatGPT can actually understand a certain kind of compressed text very well[1].
If you think about this problem from the perspective of 'LLMs is a Compressor', it becomes even more logical. That is, the more confident parts of the prompt don't need to be given to LLMs, as they can guess them from the context.
This is also a core starting point of our series of works.
And the acceleration of inference and saving of API cost brought by compression are just some by-products of achieving this goal, but these by-products are already very attractive.
In the work of LongLLMLingua, we discussed the phenomenon of low information density in prompts under Long Context Scenarios, and further utilized the relationship between information density and position and LLMs performance, and proposed a Question-Aware method to enhance LLMs' ability to perceive key information.
Next, I will introduce these two works separately.
LLMLingua
I personally really like this work, we have done a lot of detailed analysis in it and made some interesting findings.
In the paper, we try to answer the following questions, but some interesting findings may be overlooked because they are in later positions, or even in the appendix.
- How should we design a prompt compression algorithm that can maximize the compression of the prompt without affecting the performance of LLMs?
- Can this compressed prompt be directly used in downstream tasks?
- How is its generalization?
- Is there any evidence that Black-box LLMs can understand this compressed prompt?
- Is there an upper limit to this compression method?
- Why not use GPT-X to do this?
The first is how to systematically design a Prompt Compression method. Our goal is to make it directly usable, without the need for additional training for LLMs, and to balance the relationship between language integrity and compression ratio.
We thought of a series of PPL-based methods in OoD, and the information in OoD happens to be the valid information that Prompt gives to LLMs.
This approach will be different from Token Pruning/Merge, or Soft prompt based method, so that there is hope to directly use the compressed prompt on black-box LLMs without extra training for LLMs.
But is it enough to just base it on PPL? We found that
- different components in the prompt have different sensitivities to compression. For example, the sensitivity of the System prompt and question prompt is higher;
- at high compression ratios, excessive impact on language integrity makes it difficult for LLMs to understand the information in the prompt;
- some information in the Context is redundant and repetitive, especially under ICL scenarios;
- the PPL distribution will change with the occurrence of compression;
- there needs to be some way to make small models aware of Black-box LLMs;
This is why we designed the Budget Controller, Iterative Token-level Prompt Compression, and Alignment three modules in LLMLingua, the specific details can be seen in the paper.
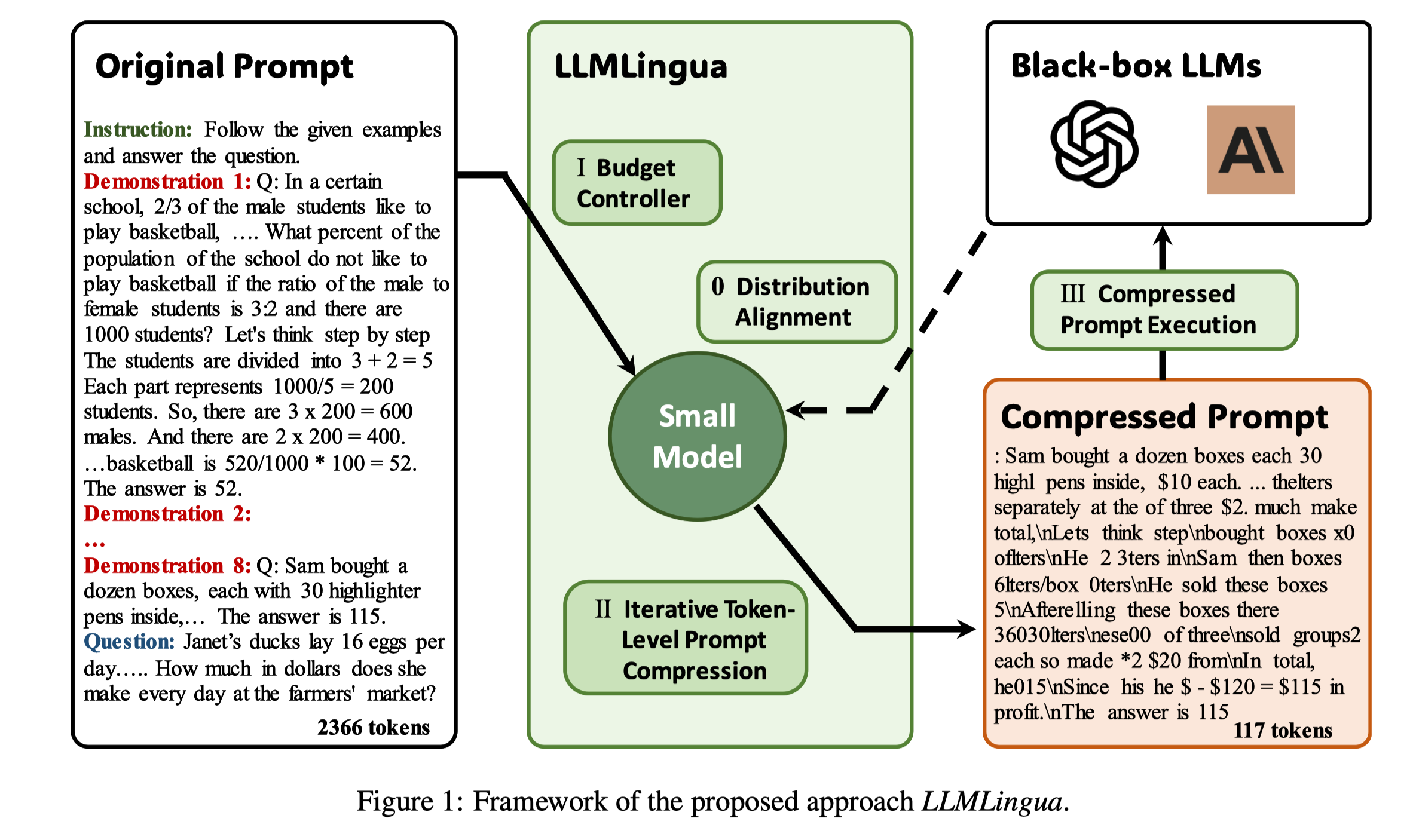
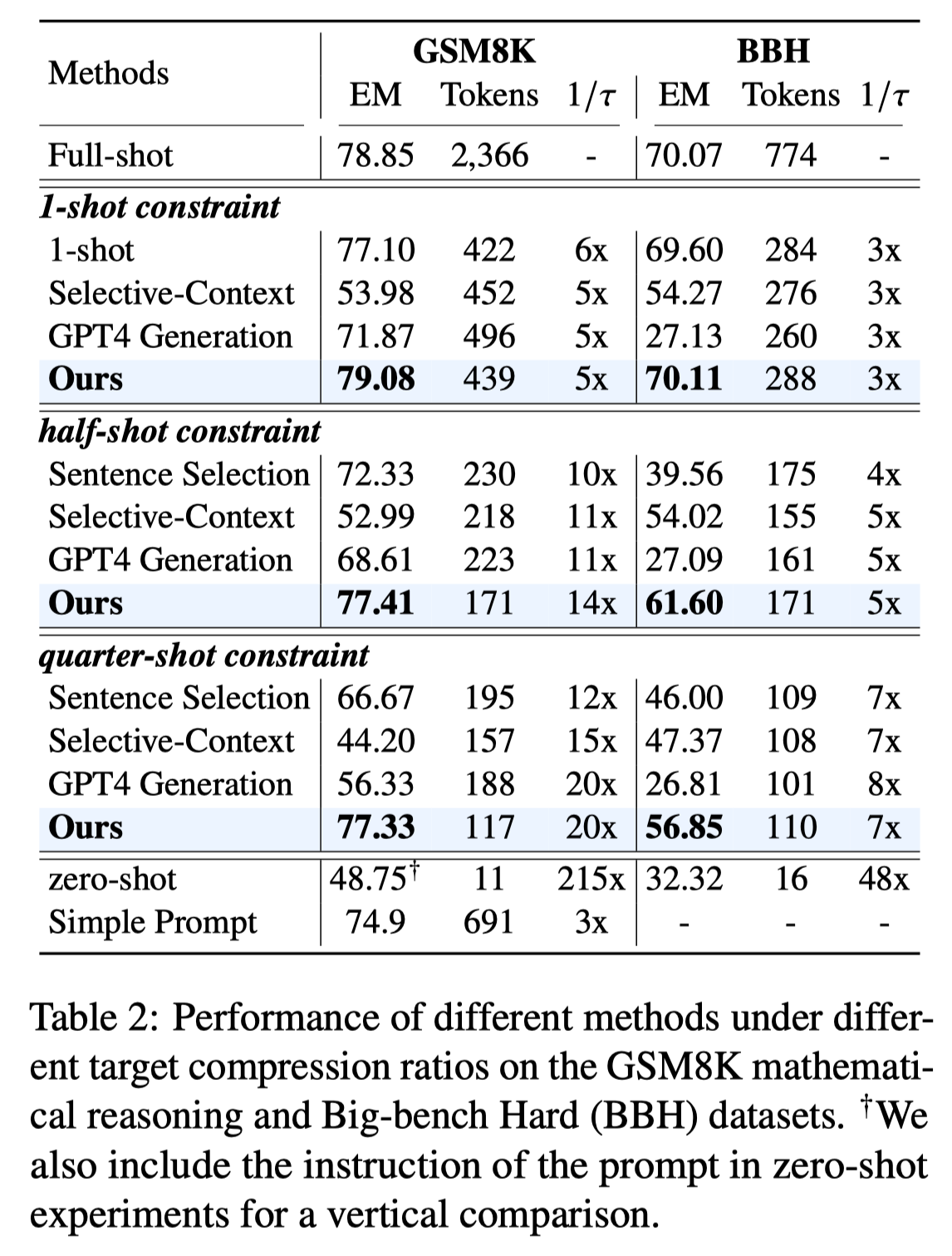
The second question is also a problem that all Efficient Method in LLMs will encounter. However, most previous works only tested on some traditional Zero-shot QA or Language Model tasks. In order to further illustrate the impact of this compressed prompt on downstream tasks, we specifically started from some unique abilities of LLMs and evaluated ICL, Reasoning, Summarization, and Conversation tasks. The results show that we can achieve a 20x compression ratio on GSM8K and almost no impact on performance. The results in Summarization and Conversation are also better than the baseline.
By the way, to answer the sixth question, we can actually see that Generation-based methods can't really preserve the key information in carefully designed prompts, it will ignore the reasoning details, and even generate completely unrelated examples, even GPT-4 is also difficult to compress prompts.
To demonstrate the generalization of LLMLingua, we tested different small language models and black-box LLMs. The results showed that due to our design, GPT2 small size models can also achieve good results. In addition, the compressed prompt can also achieve good results on Cluade, which also demonstrates the generalization of LLMLingua.

We also conducted an interesting experiment, letting GPT-4 help respond to the compressed prompts. Surprisingly, it can almost completely recover all details from those texts that are difficult for humans to understand, as shown in the figure below, it fully recovered the 9-step CoT. However, the details that can be recovered from prompts with different compression degrees are also different, which also shows that our design is reasonable.

We also found that compressing prompts not only saves input tokens, but can also further save 20%-30% of output tokens.

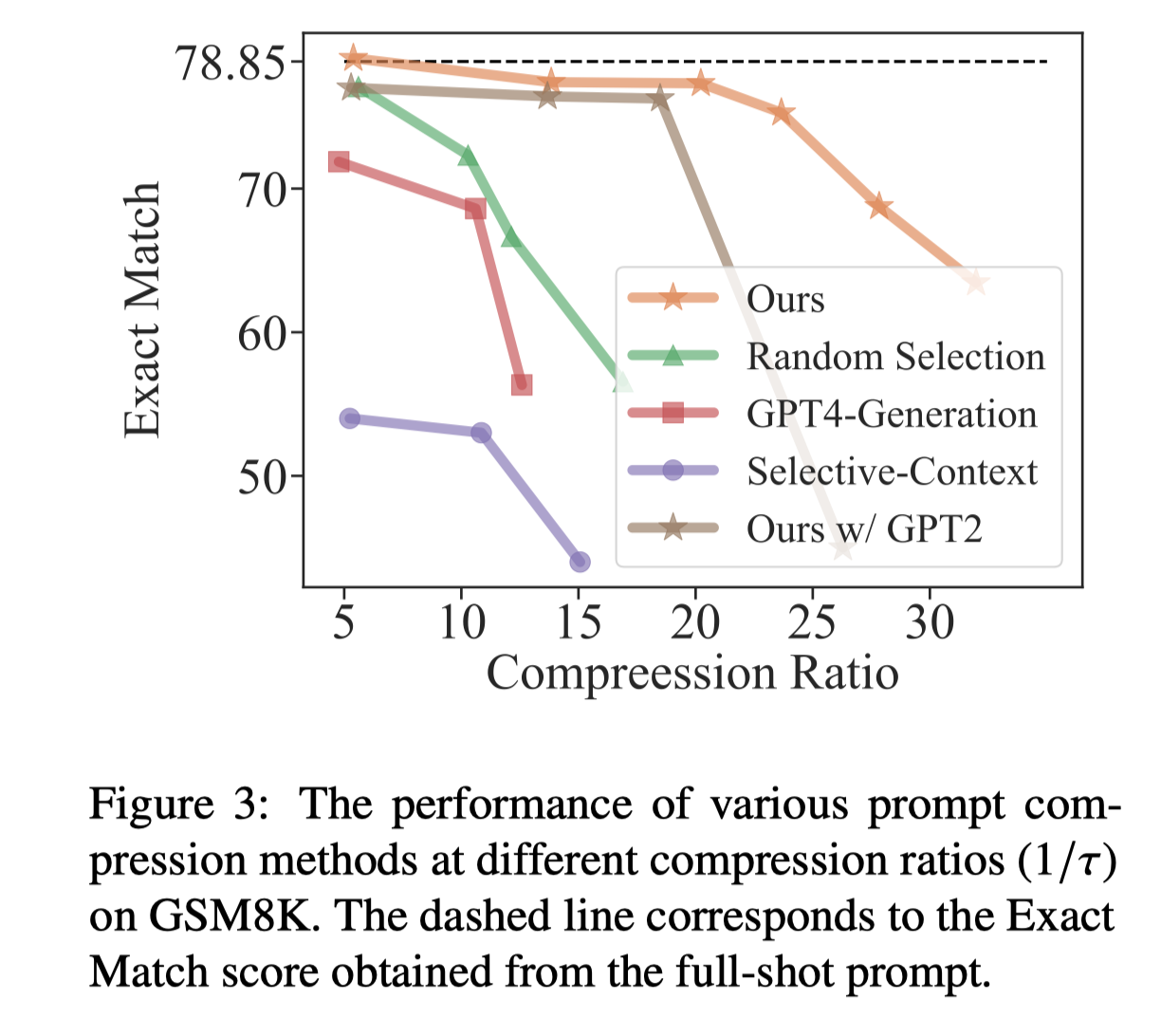
We also tried using higher compression ratios. The results showed that even with the use of LLMLingua, there will still be a severe performance drop at particularly high compression ratios.
In addition, we also applied LLMLingua to the scenario of KV-Cache Compression, and also achieved good performance.
LongLLMLingua
LongLLMLingua has a different starting point from LLMLingua. It aims not only to compress prompts to ensure less loss of precision, but also to improve the performance of LLMs in Long Context Scenarios by increasing the information density in prompts. This method is particularly suitable for the currently widely used Retrieval-Augmented Generation Method.
- Although many works now allow models to handle longer context, the growth of Context Windows can actually affect the performance of many downstream tasks[2];
- Secondly, previous work suggests that an increase in noise in prompts can affect the performance of LLMs;
- 'Lost in the middle' analyzed the impact of the position of key information in prompts on the performance of LLMs;
- Long Context Prompts can bring more API costs and latency.
Considering the above points, we believe that information density is a critical issue in Long Context Scenorias, and Prompt Compression may be one of the solutions.
However, LLMLingua or other compression-based methods are not suitable solutions. The reason is that the density of key information in Long Context is very low. It is very likely that the information entropy of the prompt itself is very high, but irrelevant. In this case, compressing the prompt will instead introduce more noise, thereby affecting performance.
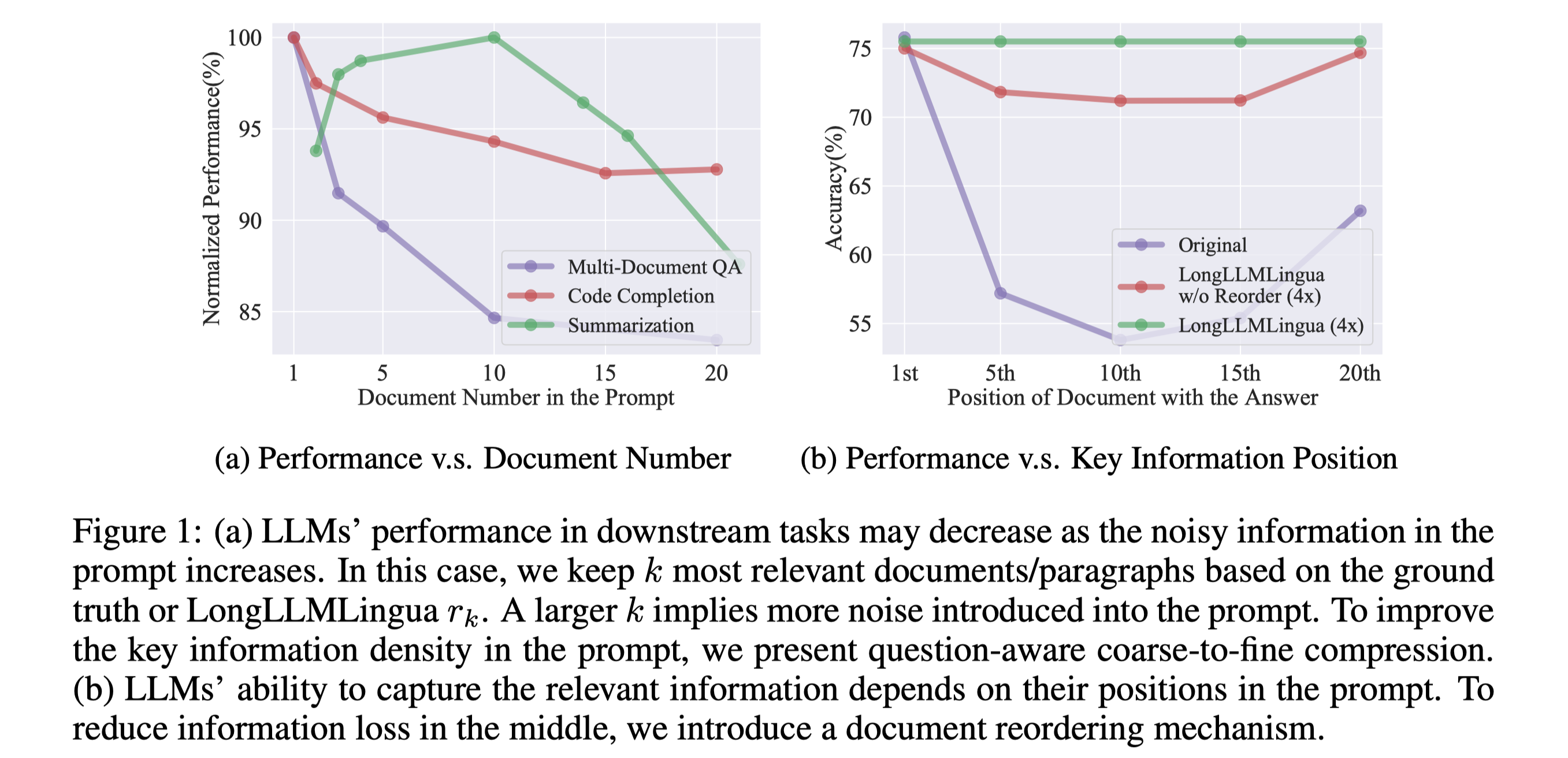
Our solution is to design a Question-Aware Coarse-fine method, which allows the compression algorithm to perceive the changes in the distribution of key information caused by the question.
For specific details, please refer to our paper. The Coarse-level method can even be used as a standalone Retrieval method, achieving good results.
In addition, we use Question-aware information to rearrange the Document, thereby alleviating the performance impact caused by 'lost in the middle'. As can be seen in the figure above, at a 4x compression rate, our method can slightly surpass the result of the ground truth at the beginning of the prompt, thereby achieving better results with less API Cost and alleviating the problem caused by 'lost in the middle'.
We also designed a dynamic compression ratio to connect the information of two granularity methods, and designed a post-processing recovery based on subsequences to recover the important information that has been compressed.
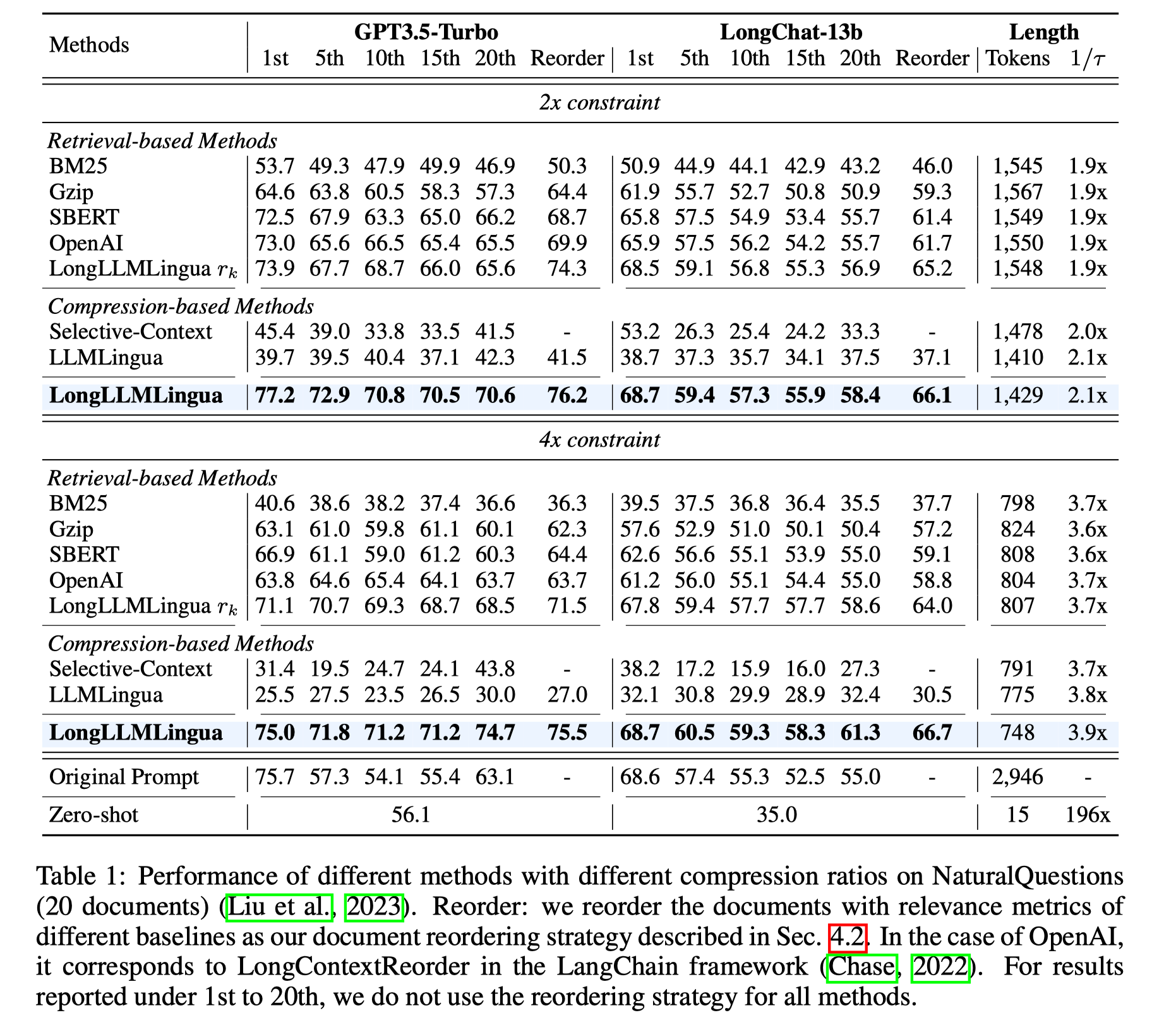
To validate the effectiveness of our method, we conducted detailed tests in Multi-Document QA and two Long Context Benchmarks.
The dataset chosen in Multi-Document QA is more in line with the actual scenario of RAG, where k documents are all highly relevant documents recalled by coarse ranking with the question.
As can be seen, our method can effectively improve performance and alleviate the phenomenon of 'lost in the middle' by increasing the information density in prompts, especially after reordering.
Secondly, even if the Coarse-level Question-aware method in LongLLMLingua is used alone, it can achieve good results, which also validates the effectiveness of our design.
We also tested different tasks in Long Context Benchmark, including Single-Document, Multi-Document, Summarization, Few-shot Learning, Synthetic, and Code Completion.
The results show that our method significantly improves tasks such as Multi-Document QA and Synthetic, and can achieve better performance at a 6x compression rate.
In addition, we also tested end-to-end Latency and the savings in API Cost.
The results show that although LongLLMLingua is slower than LLMLingua, it can still achieve actual end-to-end acceleration.
In terms of API Cost, more Cost can be saved under Long Context Scenorias, with a maximum saving of $28.5 per 1k samples.

FQA
Will different Tokenizers between different LLMs affect the compression effect?
In fact, the Tokenizer between the small model and the large model we use is completely different, but it does not affect the large model's understanding of the compressed prompt. Token-level Compression is to further perceive the important distribution of tokens in prompts in LLMs.After seeing so many compressed examples, do you think humans can summarize a certain grammar?
I think it's very difficult. Natural Language itself has certain grammatical rules, but what LLMLingua contains is grammar + world Knowledge, and this kind of Knowledge is difficult to be fully mastered by certain people.Why can LLMs understand Compressed Prompts?
Our current understanding is that because the world Knowledge is the same, different LLMs are actually approximations to the same Knowledge Space, and different LLMs can approximate to different degrees (which can be seen as the compression rate of LLMs).Can traditional compression algorithms do Prompt Compression?
In fact, we think it is difficult to do Prompt Compression directly, because the token number of the compressed prompt is likely not to decrease, and LLMs do not understand this format of information very well. However, traditional compression algorithms can be regarded as some kind of Retrieval-based Method to do Coarse-level prompt compression.Can the prompt be converted into a high-entropy language and then compressed by using the different information entropy characteristics of different languages?
In theory, it is possible. The information entropy difference in different languages is very large. But this depends on whether the translation System can retain the original information, and whether the black-box LLMs can perform similarly to the source language.
After completing LLMLingua, the anonymous policy of *CL gave us plenty of time to think. Here, we would like to thank some colleagues inside the company who have raised many meaningful questions about our work. These questions have also helped us better understand our work and future direction.
Welcome everyone to communicate with us, and also welcome everyone to experience our demo and code.
[1] A certain Twitter [2] Effective long-context scaling of foundation models.