LLMLingua 及 LongLLMLingua: 从压缩Prompt出发,探究专属于 LLMs 的语言,以及Long Context 下的方案
Tl;DR:
各个场景的cases,demo以及code见右 欢迎大家体验使用 => https://llmlingua.com/
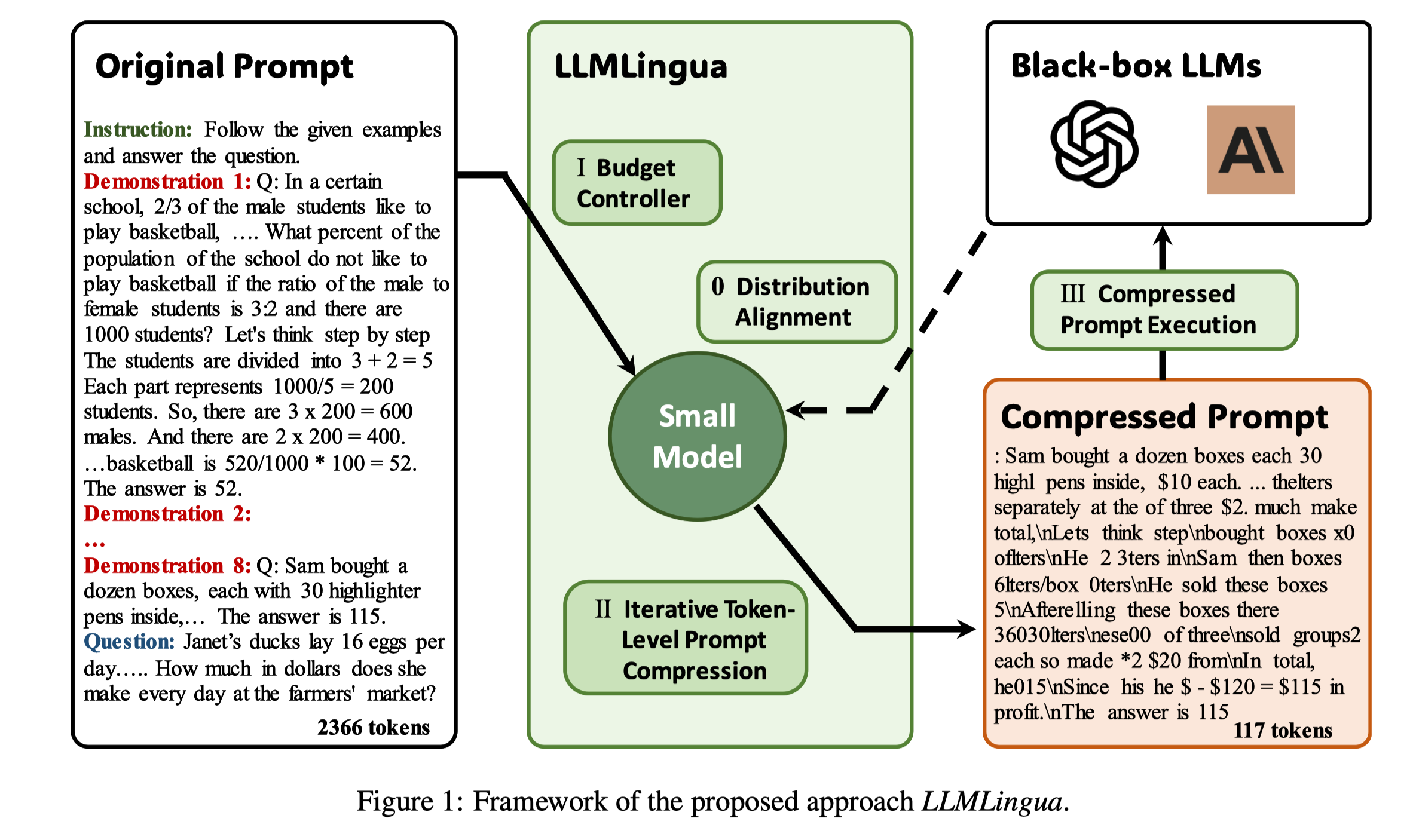
LLMLingua, 利用经过Alignment的well-trained的小的语言模型,例如GPT2-small或者LLaMA-7B,来检测和剔除prompt中的不重要token,将其转化为一种人类很难理解但是LLMs能很好理解的形势。并且这种被压缩的prompt可以直接用在black-box LLMs中,实现最高20倍的压缩,且几乎不影响下游任务性能,尤其是LLMs特有的能力,例如ICL,Reasoning等。
LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models (EMNLP 2023).
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang and Lili Qiu
LongLLMLingua, 利用Prompt 压缩增强LLMs在Long Context Scenarios下感知prompt中关键信息的能力,能够有效缓解Lost in the Middle, 十分适合RAG场景中使用。实现每1k个样本节省最高$28.5(GPT-3.5-Turbo, 4的话这个值还能x10),并且还能提升LLMs的性能。
LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression (Under Review).
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang and Lili Qiu
以下内容仅代表个人观点,不代表我所在公司或者团队的观点。
既然是博客,我们就换一种方式从high level角度讲一下我们对这个工作的理解。
首先,感谢@九号同学之前的分享,启发我们在这个topic上面做的一些工作。
标题以及LLMLingua的名字其实表达的是我们的一个goal,通过某种方式,构造一种专属于LLMs的语言。
这种语言很有可能人类很难理解,但是LLMs可以很好的理解,从而可以在这种语言上面做一些有趣的事情。
比如说用更少的比特数传递更多的信息,甚至可以传递给LLMs更高效的信息,从而提升LLMs的性能。
而我们选择了从Prompt压缩这条路来接近这个goal。
而且通过Prompt压缩来做这件事非常Make Sense,其一是因为Natrual Language本身是冗余的,尤其是口语下,第二是ChatGPT实际上能很好的理解某种被压缩的文字[1].
如果从LLMs is Compressor 角度来想这个问题,会变得更顺理成章。即prompt中更高置信的部分token完全不需要交给LLMs,他也能从上下文中猜测出来。
这也就是我们这系列工作的一个核心出发点。
而压缩带来的Inference 加速,API Cost节省都是实现这个goal的一些副产物,只是这些副产物已经非常吸引人了。
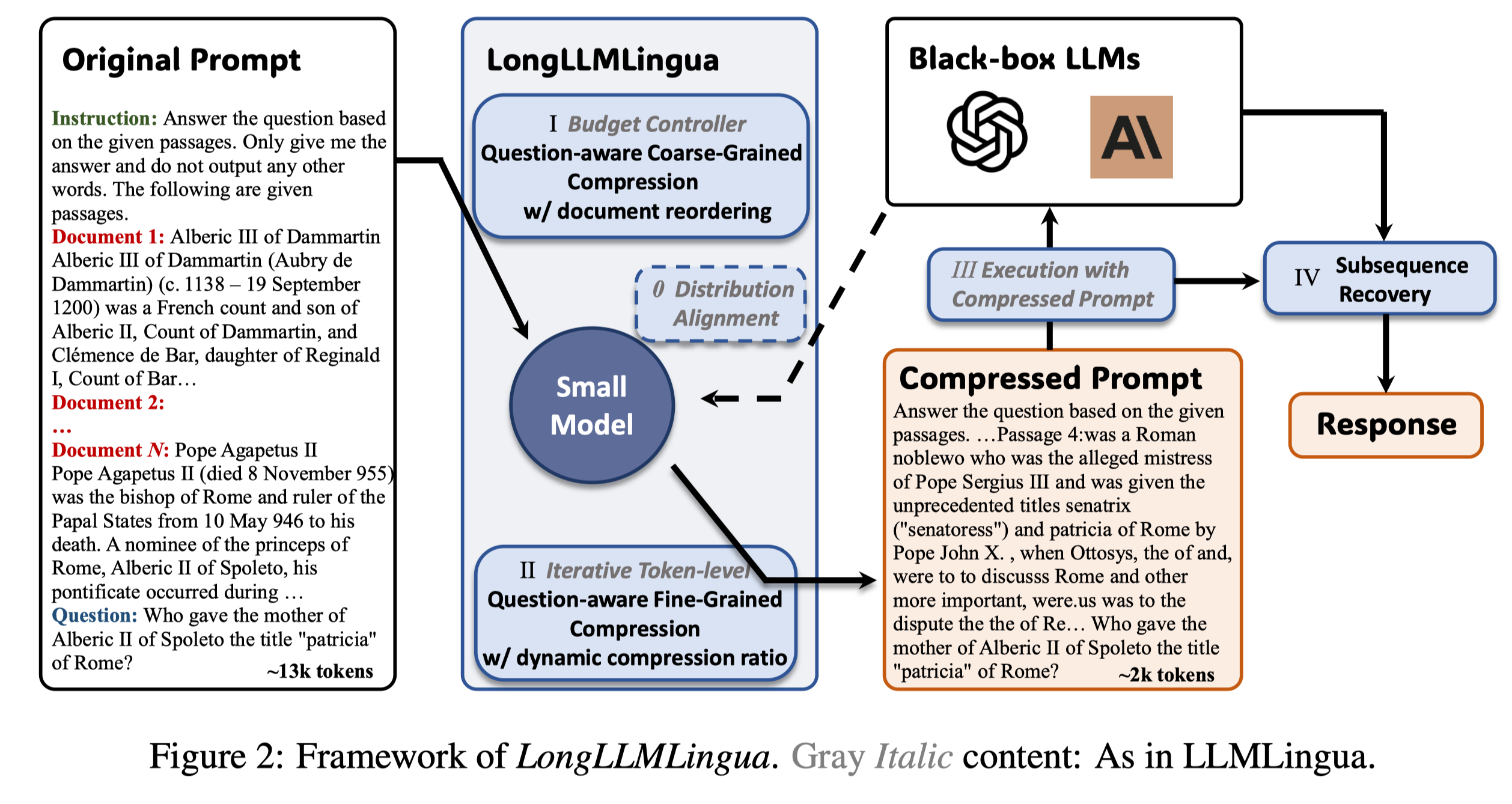
而在LongLLMLingua这篇工作中,我们讨论了Long Context Scenoias 下prompt低信息密度的现象,并进一步利用了信息密度及位置与LLMs performance的关系,提出了一种Question-Aware 的方法来增强LLMs 感知关键信息的能力。
接下来我会分别介绍这两个工作。
LLMLingua
我个人是非常喜欢这篇工作,我们在这篇中做了很多细致的分析,得到了一些很有趣的发现。
Paper里我们试图去回答以下几个问题,不过可能有些有趣的发现因为在较后的位置,甚至是附录,可能会被大家忽略。
- 我们应该如何去设计一个prompt 压缩算法,从而能够最大化的压缩prompt,同时又不影响LLMs的性能。
- 这种被压缩的prompt能直接用在下游任务中吗?
- 它的泛化性怎么样?
- 有什么证据能证明Black-box LLMs能理解这种被压缩的prompt?
- 这种压缩方法的有上界吗?
- 为什么不用GPT-X来做这件事?
第一是如何去系统的设计一个Prompt Compression方法,我们的Goal是能直接用,不需要对LLMs额外的训练,而且能平衡语言完整性和压缩率之间的关系。
我们想到了OoD里面基于PPL的一系列方法,OoD的信息正好是Prompt给到LLMs的有效信息。
这条路会有别于Token Pruning/Merge, 亦或是Soft prompt based method, 从而有希望在不对LLMs进行额外训练的情况下,直接将被压缩的prompt用在black-box LLMs上。
但仅仅基于ppl就够了么?我们发现
- prompt中不同成分对于压缩的敏感程度是不同的,例如System prompt,question prompt的敏感度更高;
- 高压缩率下,过度影响语言完整性,会让LLMs难以理解prompt中的信息;
- 部分Context 中的信息是冗余重复的,尤其是ICL场景下;
- PPL 分布会随着压缩的发生而发生改变;
- 需要有某种方式让小模型aware Black-box LLMs;
这也就是我们在LLMLingua中设计了Budget Controller,Iterative Token-level Prompt Compression, Alignment 三个module的原因,具体细节可见paper。
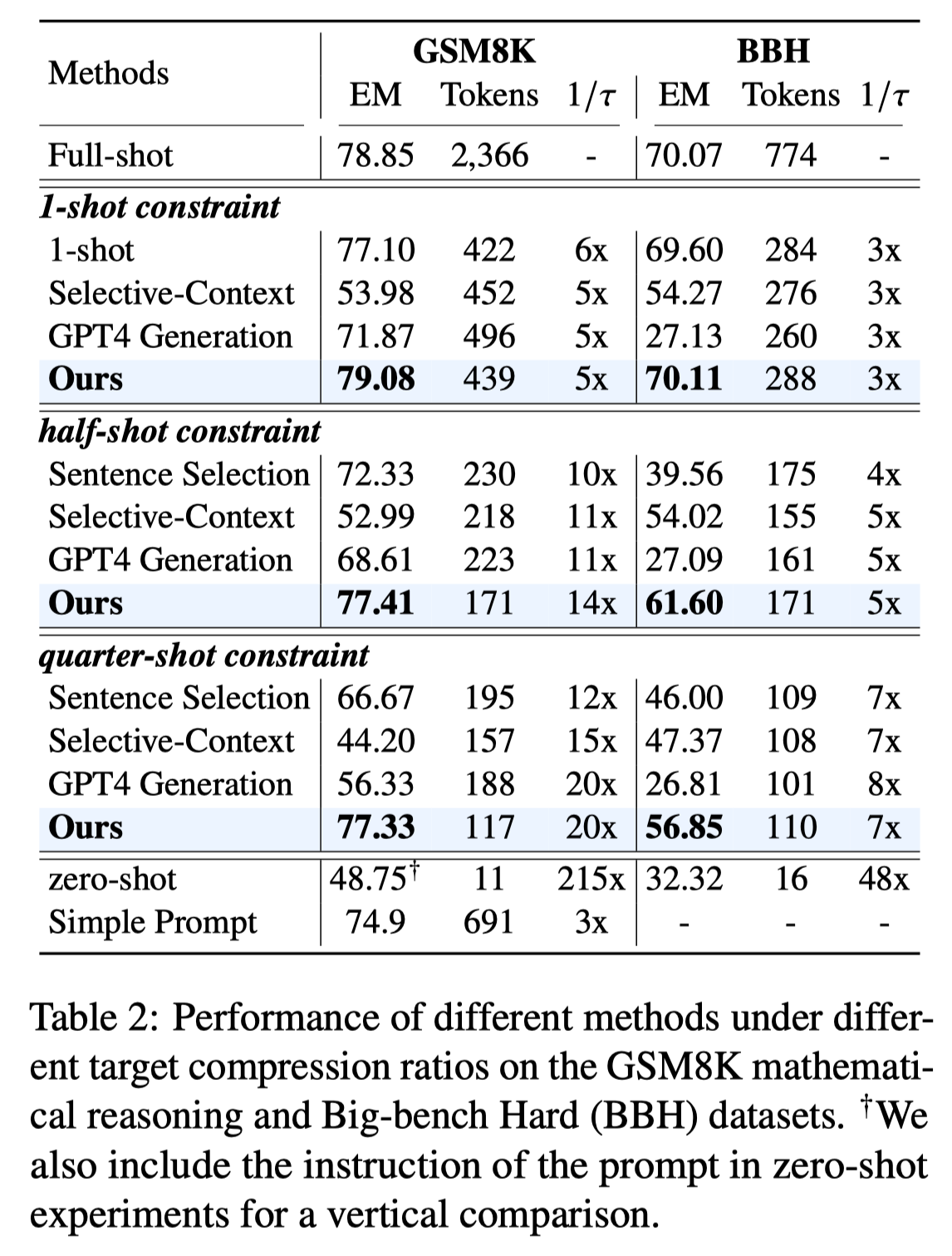
第二个问题也是所有Efficient Method in LLMs都会遇到的问题,不过之前大部分工作也只是在一些传统的Zero-shot QA或者Language Model task上进行测试,为了进一步说明这种被压缩prompt对于下游任务的影响,我们专门从LLMs特有的一些能力出发,评测了ICL,Reasoning,Summarization,和Conversation这些任务。结果显示我们在GSM8K上可以做到20x的压缩比,并且几乎不影响performance。在Summarization和Conversatio的结果也比baseline要优。
顺带回答第六个问题,其实可以看见Generation-based的方法实际上不能很好的保留精心设计的prompt中的关键信息,它会忽略推理细节,甚至生成一个完全不相关的examples,即使是GPT-4 也很难完成压缩prompt这件事。
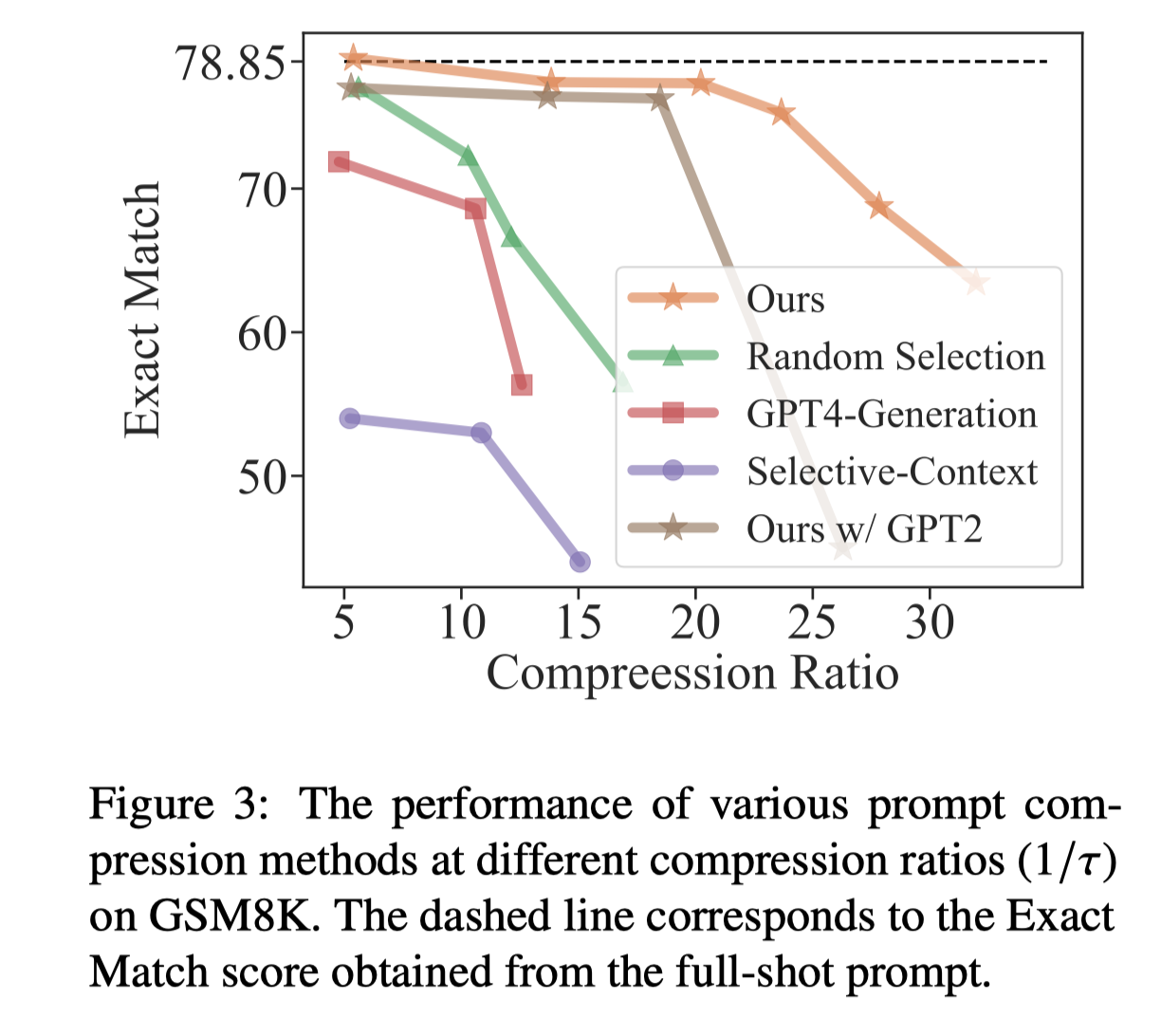
为了证明LLMLingua的泛化性,我们测试了不同small language model 和black-box LLMs,结果显示由于我们的设计GPT2 small size的模型也能取得不错的结果。此外,被压缩的prompt也能在Cluade上取得不错的结果,这也说明了LLMLingua的泛化性。

我们还做了一个有趣的实验,让GPT-4 去帮助回复被压缩之后的prompt,惊奇的发现,居然可以从那些人类很难理解的文本中几乎完全的恢复出所有细节,如下图完全恢复出了9-steps CoT。不过不同压缩程度的prompt能恢复的细节也不同,这也说明了我们的设计是合理的。

我们还发现压缩Prompt不仅能节省Input tokens,还能进一步节省20%-30% output tokens.

我们也尝试使用了更多的压缩率,结果显示即使是利用了LLMLingua,在特别大的压缩率下仍然会出现特别剧烈的performance drop。
除此之外,我们还将LLMLingua apply到KV-Cache Compression的场景,也能取得不错的performance。
LongLLMLingua
LongLLMLingua 出发点和LLMLingua就不太一样了,不只是想要压缩prompt保证少掉精度,而是想要在Long Context Scenarios下,通过提升prompt中的信息密度,从而提升LLMs的性能。
这个方法特别适合现在普遍使用的Retrieval-Augmented Generation Method。
- 虽然现在有很多工作让模型能够处理更长的context,但是Context Windows 的增长反而会影响很多下游任务的performance[2];
- 其次,之前的工作表面prompt中noise的增多,会影响LLMs的性能;
- Lost in the middle 中分析了prompt 中关键信息的位置对于LLMs的性能的影响;
- Long Context Prompt 会带来更多的API Cost和latency;
综合以上几点,我们觉得Long Context Scenorias 中信息密度是一个非常关键的问题,Prompt Compression可能是其中的一个解决方案。
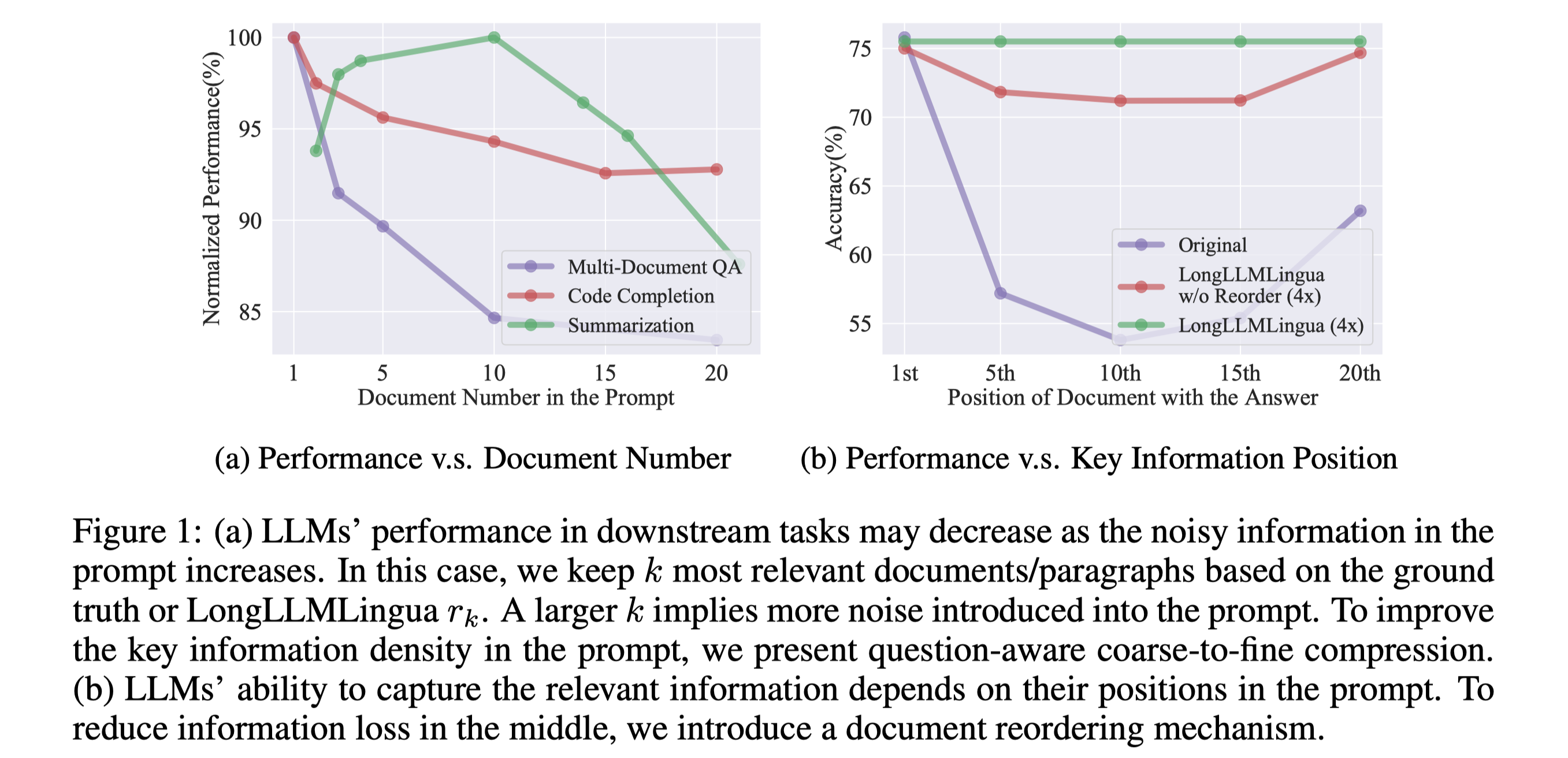
但是LLMLingua或者其他Compression-based 的method 并不是一个合适的解决方案,原因是Long Context 中关键信息的密度很低,很有可能prompt本身的信息熵很高,但是不相关,这样压缩prompt反而会引入更多的噪声,从而影响performance。
我们的解决方案是,通过设计了Question-Aware Coarse-fine的方法,让压缩算法能够感知到因为question带来的关键信息分布的变化。
具体细节可以参考我们的paper。其中Coarse-level的方法甚至还能单独拿来作为一个Retrieval method,取得不错的效果。
除此之外,我们利用Question-aware 的信息,对Document 进行重排,从而缓解lost in the middle带来的performance影响。可以看到如上右图,在4x压缩率,我们的方法能够略微超过ground truth 位于prompt 开头的结果,从而用更少的API Cost取得更好的结果,缓解lost in the middle 带来的问题。
我们还设计了dynamic compression ratio 来串联两个粒度方法的信息,设计了一个基于子序列的后处理recovery来恢复被压缩的重要信息。
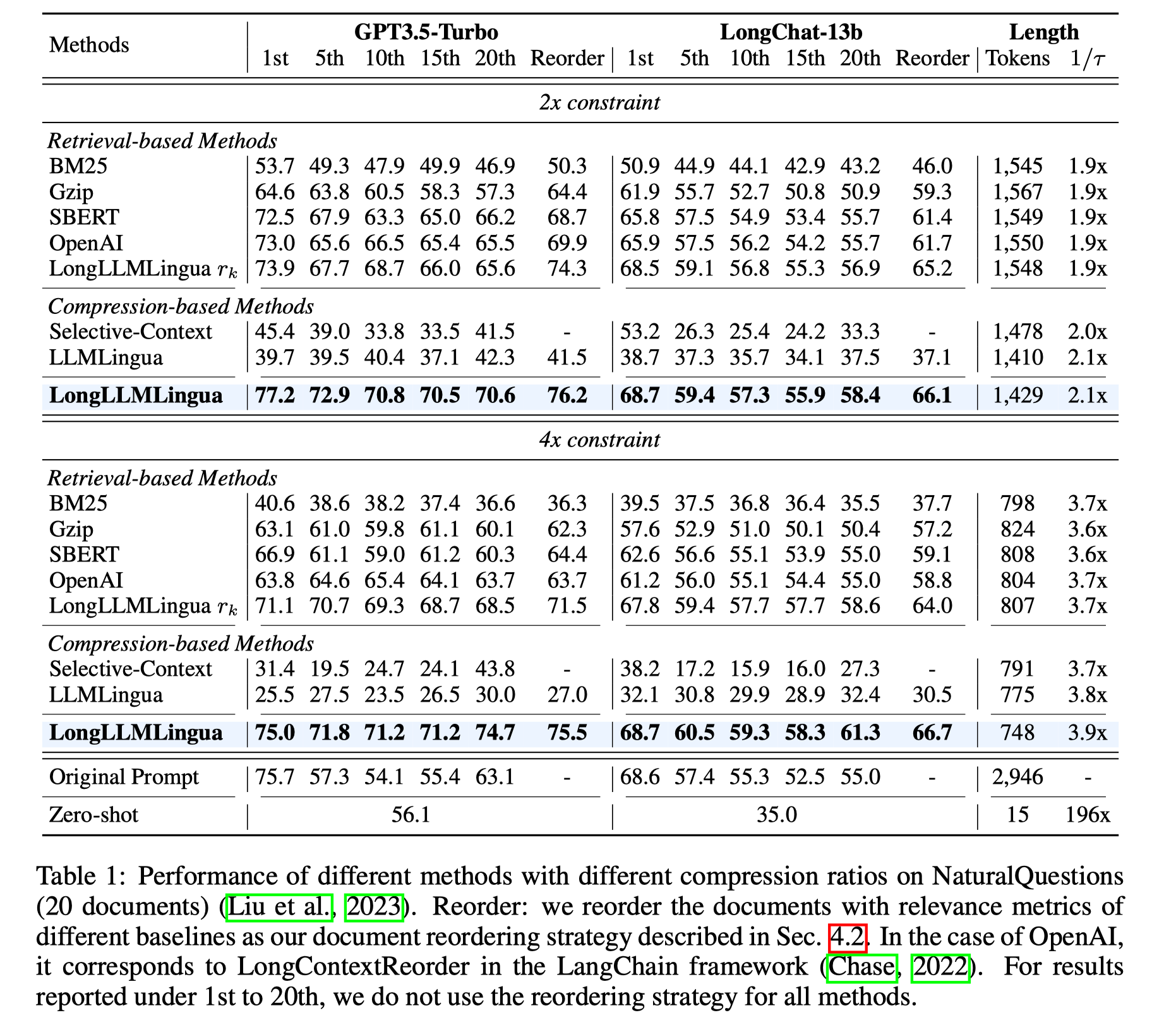
为了证明我们方法的有效性,我们在Multi-Document QA和两个Long Context Benchmark 中进行了细致的测试。
其中Multi-Document QA中选用的dataset 更贴合RAG实际场景,k个document均为粗排召回与question十分相关的document。
可以看到我们的方法通过提高prompt中的信息密度能够有效的提升performance,缓解lost in the middle现象,尤其是经过reorder之后。
其次,即使单独使用LongLLMLingua中Coarse-level Question-aware的方法,也能取得不错的效果,这也说明了我们的设计有效性。
我们还测试了Long Context Benchmark中的不同tasks,包括Single-Document, Multi-Document, Summarization, Few-shot Learning, Synthetic和Code补全。
结果显示我们的方法在Multi-Document QA, Synthetic等任务上提升明显,能够在6x压缩率下获得更好的performance。
除此之外,我们还测试了端到端Latency,和API Cost节省情况。
结果显示,LongLLMLingua 虽然会比LLMLingua慢,但仍然能拿到实际的端到端加速。
API Cost方面,Long Context Scenorias 下能够节省更多的Cost,最多每1k个样本节省$28.5。

FQA
不同LLMs之间Tokenizer 不同会影响压缩效果吗?
实际上我们用的小模型和大模型之间的Tokenizer完全不同,但是并不影响大模型对compressed prompt的理解。Token-level Compression是为了进一步感知LLMs中对于prompt的token的重要分布。你看过那么多压缩的example,你觉得人能总结出某种语法吗?
我觉得十分困难,Natural Language本身有一定的语法规则,但是LLMLingua所蕴含的是语法+world Knowledge,这种Knowledge是很难由某些特定人完全掌握的。为什么LLMs能理解Compressed Prompt?
我们现在的理解是因为world Knowledge是相同的,不同的LLMs其实都是对于同一个Knowledge Space的逼近,不同LLMs能够逼近的程度不同(可以看成是LLMs的压缩率)。传统压缩算法能做Prompt Compression吗?
实际上我们觉得直接做Prompt Compression比较困难,因为压缩完的prompt很有可能token数量不会减少,而且LLMs并不会很好的理解这种格式的信息。但是可以将传统压缩算法看做是某种Retrieval-based Method 来做Coarse-level的prompt compression。能利用不同语言信息熵不同的特点,将prompt转换为信息熵高的语言再压缩吗?
理论上是可以的,不同语言中的信息熵差异非常大。但是这取决于translation System能够保留住原有信息,且black-box LLMs对于对应language能够有与源语言相似的performance。
在完成LLMLingua之后,由于*CL的匿名政策,让我们有了充足的时间去思考。在这里感谢公司内部的一些同事,对我们的工作提出了很多有意义的问题,这些问题也帮助我们更好的理解我们的工作,以及未来的方向。
欢迎大家我们交流,也欢迎大家体验我们的demo和code。
[1] 某个Twitter [2] Effective long-context scaling of foundation models.